I recently tried to download the Weekly Patterns - Foot Traffic - Advan Product Package - Dewey (deweydata.io) via API but I’m unable to download it. I was able to download the data back in November. I’m still able to download the other Advan data via same API apart from Weekly Patterns - Foot Traffic.
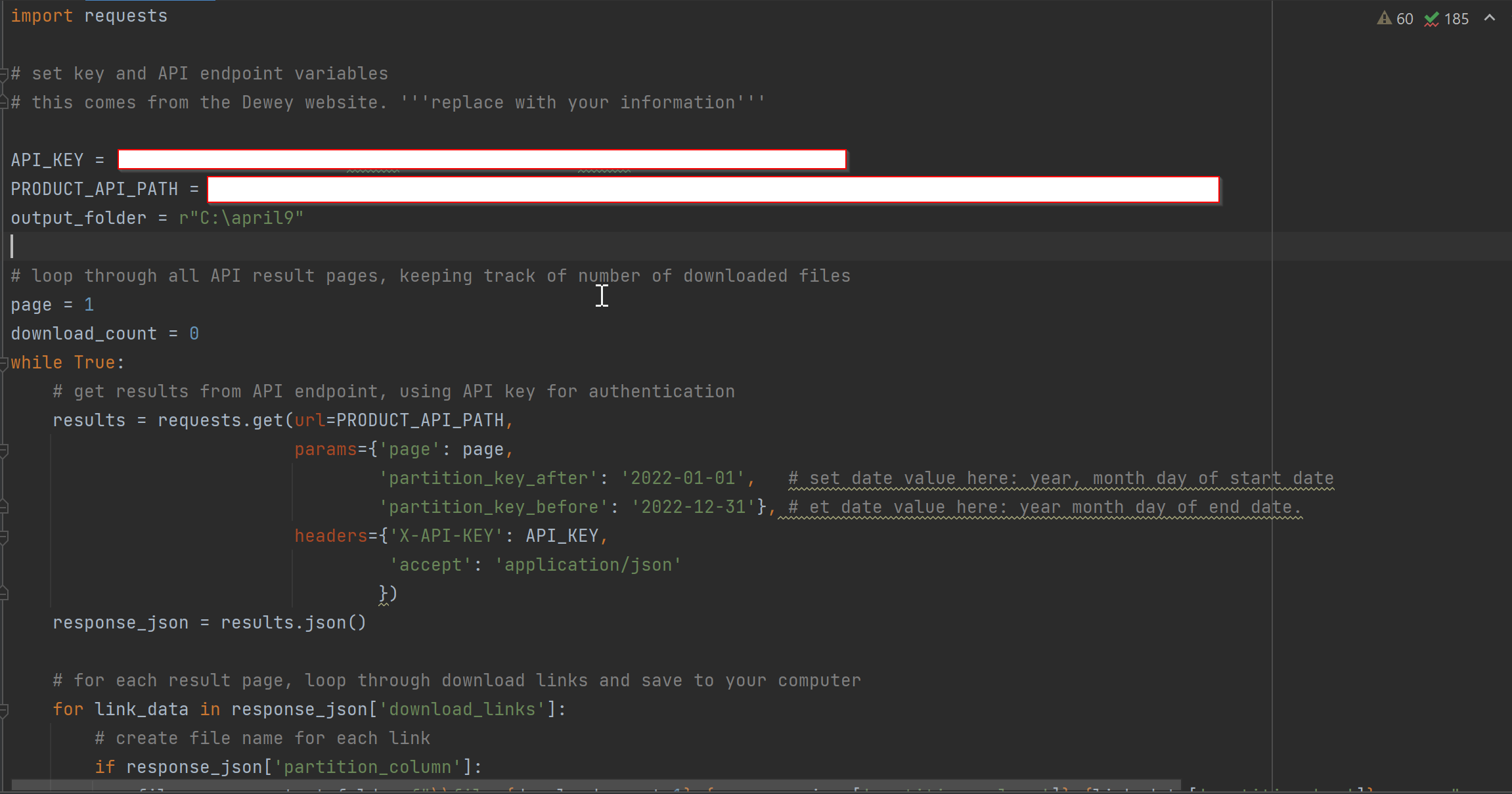
This is code I’m using to download it. It’s working for other Advan datas.
For downloading the data
import requests library to call API endpoint
import requests
set key and API endpoint variables
this comes from the Dewey website. ‘’‘replace with your information’‘’
API_KEY = “XXXXXXXX”
PRODUCT_API_PATH = “xxxxxxxx”
output_folder = r"C:\april9"
loop through all API result pages, keeping track of number of downloaded files
page = 1
download_count = 0
while True:
# get results from API endpoint, using API key for authentication
results = requests.get(url=PRODUCT_API_PATH,
params={‘page’: page,
‘partition_key_after’: ‘2022-01-01’, # set date value here: year, month day of start date
‘partition_key_before’: ‘2022-12-31’}, # et date value here: year month day of end date.
headers={‘X-API-KEY’: API_KEY,
‘accept’: ‘application/json’
})
response_json = results.json()
# for each result page, loop through download links and save to your computer
for link_data in response_json['download_links']:
# create file name for each link
if response_json['partition_column']:
file_name = output_folder+f"\\file-{download_count+1}-{response_json['partition_column']}-{link_data['partition_key']}.csv.gz"
else:
file_name = f"file-{download_count+1}.csv.gz"
print(f'Downloading file {file_name}...')
# loop through download links and save to your computer
data = requests.get(link_data['link'])
with open(file_name, 'wb') as file:
print (file_name)
file.write(data.content)
download_count += 1
# only continue if there are more result pages to process
total_pages = response_json['total_pages']
if page >= total_pages:
break
page += 1
print(f"Successfully downloaded {download_count} files.")