Some Dewey data includes JSON type key-value pair data. For example, Advan monthly patterns have field POPULARITY_BY_DAY and the data looks like
{"Monday":166,"Tuesday":174,"Wednesday":191,"Thursday":205,"Friday":194,"Saturday":26,"Sunday":16}
{"Monday":6,"Tuesday":9,"Wednesday":17,"Thursday":22,"Friday":9,"Saturday":4,"Sunday":6}
{"Monday":105,"Tuesday":143,"Wednesday":194,"Thursday":186,"Friday":112,"Saturday":37,"Sunday":22}
These are JSON texts.
deweydatar library has a function keyval_to_df to convert those key-value pair data to a data.frame.
To install deweydatar (version 0.1.2 or later),
# Load "devtools" library (install it first, if don't have it)
library(devtools)
# Install deweydatar package from GitHub
install_github("Dewey-Data/deweydatar")
and see here for more details.
Once you have the library,
apikey_ = "Your API key"
# Advan product path
pp_advan_mp = "Your API endpoint for Advan monthly patterns"
data = read_sample_data0(apikey_, pp_advan_mp, 100)
I will choose the first 6 rows of POPULARITY_BY_DAY as an example.
keyval_data = data$POPULARITY_BY_DAY[1:6]
This column has Monday, Tuesday, Wednesday, Thursday, Friday, Saturday and Sunday as key values always. When the JSON format is regular, meaning each row has same keys in the same order, and there is no error in the data column, then you can call keval_to_df with asis=TRUE
# When fixed format with no error
df = keyval_to_df(keyval_data, asis = T)
df
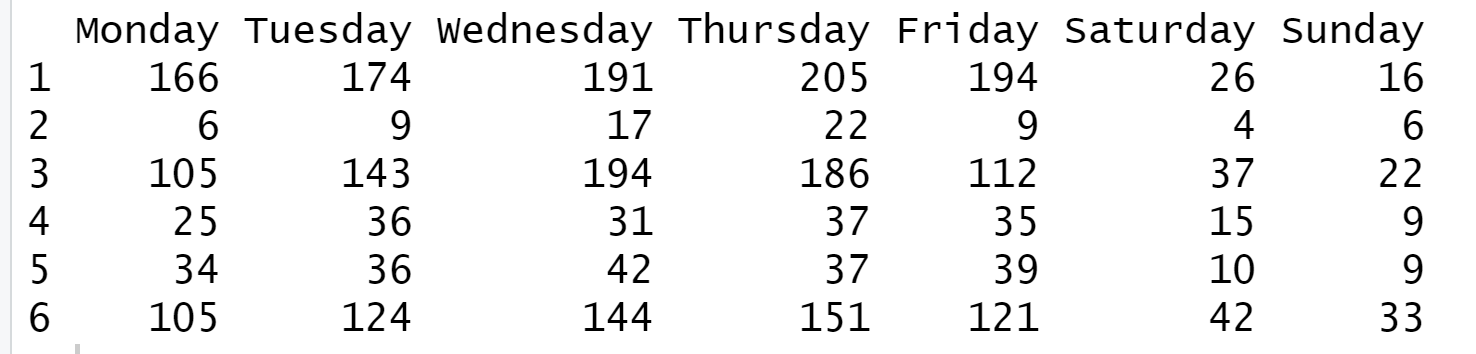
You can select only some keys out of full keys.
# Select keys
df = keyval_to_df(keyval_data, keys = c("Saturday", "Tuesday"))
df

This example column is regular but in some other data fields, keys are irregular in each row (one example is provided later). For example, row 1 may have Saturday and Tuesday while row 2 has Saturday, Tuesday and Holiday. When you choose non-existing keys, the function will fill that key with NAs.
# Select not existing keys
df = keyval_to_df(keyval_data, keys = c("Saturday", "Holiday", "Tuesday"))
df
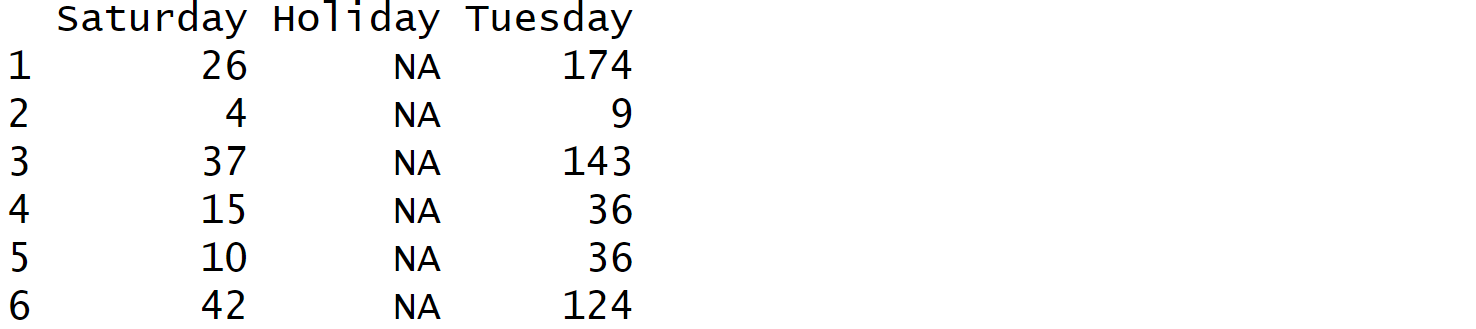
There are cases when certain rows have non-JSON text or error such as blank text (""). I intentionally made keyval_data[3] to "". If you run this ```asis = TRUE``, it will throw an error because the function does not know what to do with the data.
# When data has error JSON
keyval_data[3] = ""
df = keyval_to_df(keyval_data, asis = T)

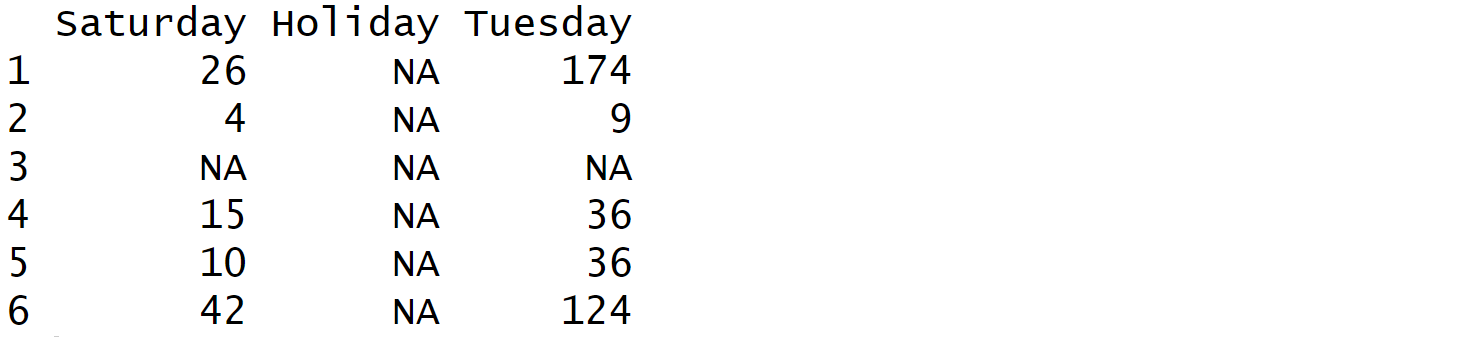
You can provide specific keys to way around this error. Below code will fill the 3rd row with all NAs to populate a data.frame.
df = keyval_to_df(keyval_data, keys = c("Saturday", "Holiday", "Tuesday"))
df
Some columns have irregular keys. For example, RELATED_SAME_MONTH_BRAND has different brand names as keys in each row. Here is an example.
{"Starbucks":540,"Western Union":538,"Keyme Kiosk":507,"CVS":391,"CVS Pharmacy":385,"Rotary Club":356,"Wetzel's Pretzels":355,"Shoe Palace":350,"Shell Oil":349,"Chevron":346,"Vans":333,"Farmers Insurance Group":331,"76":320,"Cambria Suites":317,"Charley's":312,"Zales":303,"Sunglass Hut":301,"Jersey Mike's":298,"LIDS":297}
{"Legacy Health":47,"Western Union":40,"Starbucks":38,"Fred Meyer":25,"Chevron":24,"Kroger Pharmacy":24,"76":23,"Keyme Kiosk":21,"Fred Meyer Jewelers":21,"Jamba":20,"Subway":19,"Costco":19,"Hertz":19,"Costco Optical":18,"Fred Meyer Pharmacy":18,"Costco Pharmacy":18,"McDonald's":18,"U.S. Bank":17,"CVS Pharmacy":17}
{"Hanger Prosthetics & Orthotics":488,"Western Union":462,"Starbucks":379,"Kroger Pharmacy":316,"Walmart":315,"Shell Oil":311,"Fry's Food & Drug Stores":310,"Keyme Kiosk":304,"Walmart Vision Center":293,"Walmart Pharmacy":292,"Jackson Hewitt Tax Service":284,"Walmart Photo Center":283,"Circle K":272,"CVS":240,"Walgreens Pharmacy":230,"Walgreens":221,"Chevron":211,"CVS Pharmacy":211,"Panda Express":207}
If you want to extract specific brands, you can call
# Extract specific keys
keyval_data = data$RELATED_SAME_MONTH_BRAND[1:6]
df = keyval_to_df(keyval_data,
keys = c("Starbucks", "Walmart", "Target", "McDonald's"))
df

Finally, some Dewey data has key-value pair but not in JSON format. Here is an example for pass_by data.
pp_passby_visitors = "Your API end point"
data = read_sample_data0(apikey_, pp_passby_visitors, 100)
VISITOR_INDUSTRY column has key-value pair data but not in JSON
keyval_data = data$VISITOR_INDUSTRY[1:6]
{{"AccomFood",7.47},{"AdminSupport",4.3},{"ArtsEntsRec",1.98},{"Construct",7.49},{"Educ",8.86},{"FinancInsur",4.34},{"HealthSoc",13.03},{"Info",2.18},{"Management",0.08},{"Manuf",11.39},{"OtherPrivat",4.99},{"ProfSciTech",5.18},{"PublicAdmin",4.8},{"RealEst",1.86},{"RetTrade",11.86},{"TransWarehous",4.28},{"Utilities",0.86},{"WholeTrade",2.91}}
{{"AccomFood",7.58},{"AdminSupport",4.4},{"ArtsEntsRec",1.98},{"Construct",7.48},{"Educ",8.81},{"FinancInsur",4.34},{"HealthSoc",13.05},{"Info",2.18},{"Management",0.09},{"Manuf",11.22},{"OtherPrivat",5.02},{"ProfSciTech",5.17},{"PublicAdmin",4.86},{"RealEst",1.88},{"RetTrade",11.87},{"TransWarehous",4.31},{"Utilities",0.84},{"WholeTrade",2.92}}
{{"AccomFood",7.67},{"AdminSupport",4.32},{"ArtsEntsRec",2.2},{"Construct",6.96},{"Educ",8.92},{"FinancInsur",4.89},{"HealthSoc",12.86},{"Info",2.56},{"Management",0.1},{"Manuf",10.33},{"OtherPrivat",4.97},{"ProfSciTech",6.41},{"PublicAdmin",4.58},{"RealEst",2.09},{"RetTrade",11.59},{"TransWarehous",4.25},{"Utilities",0.75},{"WholeTrade",2.94}}
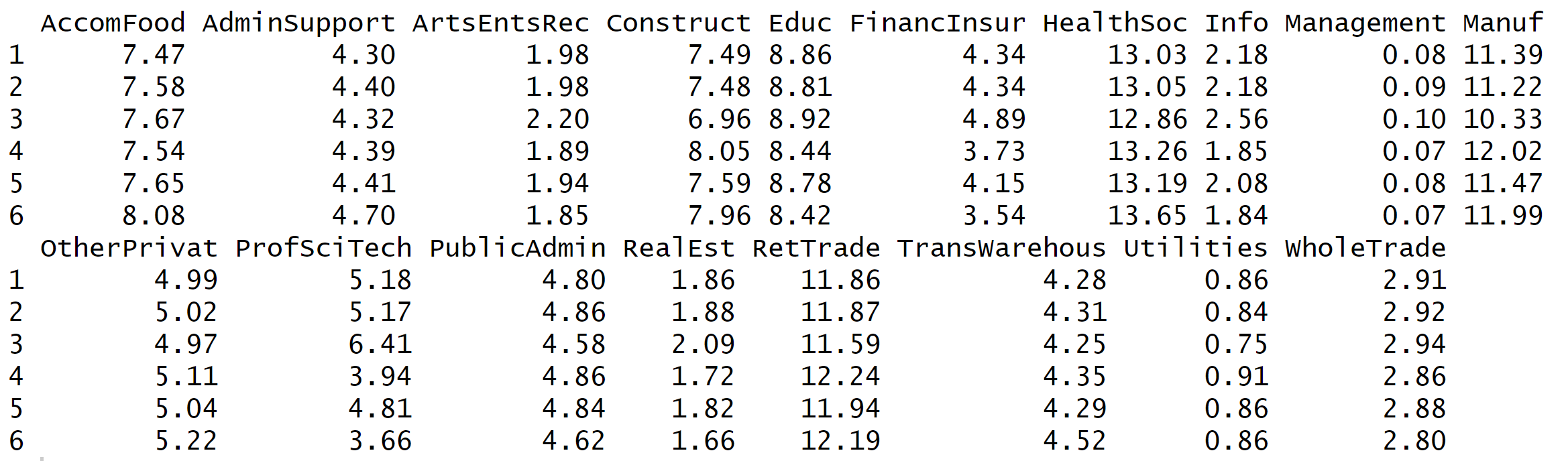
This can be populated as well by setting type="pass_by"
df = keyval_to_df(keyval_data, type = "pass_by", asis = T)
df
This can be slow for a large dataset.
Please report if you find any errors.
Thanks,