This may be the last article on bulk data download. I posted a simple version in R. I thought I made this R version referencing some Python code but I could not find it. So, I translated the R code into Python. Recently, I found this was the original Python code I referenced to create the R code. Many thanks to Dewey Data Team.
I updated the original Python code to add two download functions.
Here is the full code:
import getpass
import json
import pandas as pd
import requests
import gzip
from io import BytesIO
import traceback
import sys
DEWEY_TOKEN_URL = "https://marketplace.deweydata.io/api/auth/tks/get_token"
DEWEY_MP_ROOT = "https://marketplace.deweydata.io"
DEWEY_DATA_SUB_ROOT = "/api/data/v2/list"
DEWEY_DATA_ROOT = f"{DEWEY_MP_ROOT}{DEWEY_DATA_SUB_ROOT}"
# Get access token
def get_access_token(username, passw):
response = requests.post(url=DEWEY_TOKEN_URL, data={}, auth=(username, passw))
json_dict = json.loads(response.text)
return json_dict["access_token"]
# Return file paths in the sub_path folder
def get_file_paths(token, sub_path=""):
# sub_path = "/2018/01/01/SAFEGRAPH/MPSP"
response = requests.get((DEWEY_DATA_ROOT + sub_path),
headers={"Authorization" : "Bearer " + token})
json_text = json.loads(response.text)
response_df = pd.DataFrame.from_dict(json_text)
# response_df.tail(5)
# response_df.iloc[0:5, 0]
return response_df
# Download a single file from Dewey (src_url) to a local destination file (dest_file).
# Increase the timeout if you have a large file to download.
# Example ----------------------------------------------------------
# # Avoid including your credentials in the code.
# # You can hard type your credentials in the code as well though.
# username = getpass.getpass("User name (email address)")
# password = getpass.getpass("Password")
#
# # Get access token
# tkn = get_access_token(username, password)
# tkn
#
# # Get file paths in the "/2018/01/01/SAFEGRAPH/MPSP" sub folder.
# file_paths = get_file_paths(token=tkn, sub_path="/2018/01/01/SAFEGRAPH/MPSP")
# file_paths.head(5)
#
# # Download the first file to C:/temp/, as an example.
# # In the file_paths DataFrame,
# # file_paths.loc[0, "url"] looks like:
# # /api/data/v2/data/2018/01/01/SAFEGRAPH/MPSP/20180101-safegraph_mpsp_visit_panel_0'
# # and file_paths.loc[0, "name"] looks like:
# # visit_panel_summary.csv'.
# src_url = DEWEY_MP_ROOT + file_paths.loc[0, "url"]
# dest_file = "C:/temp/" + file_paths.loc[0, "name"]
# download_file(tkn, src_url, dest_file)
#
# # Done! Check out your "C:/temp/"
# ------------------------------------------------------------------
def download_file(token, src_url, dest_file, timeout=200):
# token = tkn
try:
response = requests.get(src_url, headers={"Authorization" : "Bearer " + token}, timeout=timeout)
open(dest_file, 'wb').write(response.content)
except:
print("Could not download the file.")
traceback.print_exc()
sys.stdout.flush()
# token = tkn
# file_url = "/api/data/v2/data/2022/12/26/ADVAN/WP/20221226-advan_wp_pat_part99_0"
# timeout = 300
def read_data(token, file_url, timeout = 300):
src_url = DEWEY_MP_ROOT + file_url
response = requests.get(src_url, headers={"Authorization": "Bearer " + token}, timeout=timeout)
try:
csv_df = pd.read_csv(BytesIO(response.content), compression="gzip")
except gzip.BadGzipFile: # not gzip file. try normal csv
csv_df = pd.read_csv(BytesIO(response.content))
except:
print("Could not read the data. Can only open gzip csv file or csv file.")
return csv_df
# Read a file from local hard drive
def read_file(file_path):
try:
csv_df = pd.read_csv(file_path, compression="gzip")
except gzip.BadGzipFile: # not gzip file. try normal csv
csv_df = pd.read_csv(file_path)
except:
print("Could not read the data. Can only open gzip csv file or csv file.")
return csv_df
# Download files recursively -----------------------------------------------
# Recursive function that returns the paths to each file available
def get_myfiles_struct(token, sub_path = ""):
#sub_path = "/2022"
response = requests.get(f"{DEWEY_DATA_ROOT}{sub_path}", headers={"Authorization": f"Bearer {token}"})
response_df = pd.DataFrame(response.json())
if response_df.shape[0] > 0:
files = response_df[response_df['directory']==False]
folders = response_df[response_df['directory']==True]
for sub_folder in folders.name.unique():
print(f"Getting folder structure: {sub_path}/{sub_folder}")
sys.stdout.flush()
sub_files, sub_folders = get_myfiles_struct(token, sub_path=f"{sub_path}/{sub_folder}")
files = pd.concat([files, sub_files])
folders = pd.concat([folders, sub_folders])
files.reset_index(drop=True, inplace=True)
folders.reset_index(drop=True, inplace=True)
return files, folders
else:
return None, None
def __ym_months_after(ym, months):
if (months == 0):
return ym
year = ym // 100
month = ym % 100
adj_mths = month + months
year = year + adj_mths // 12
month = adj_mths % 12
if(month == 0):
month = 12
year = year -1
return (year * 100 + month)
# Get myfiles structure from from_ym to to_ym
# from_ym = 202203
# to_ym = 202204
def get_myfiles_struct_period(token, from_ym, to_ym):
ym_cursor = 0
files = None
folders = None
while(True):
cur_ym = __ym_months_after(to_ym, -ym_cursor)
if(cur_ym < from_ym):
break
# download code here
#print(f"{cur_ym}")
print(f"/{cur_ym//100}/{cur_ym%100:02d}")
sys.stdout.flush() # for R console
f_struct = get_myfiles_struct(token, sub_path=f"/{cur_ym//100}/{cur_ym%100:02d}")
files = pd.concat([files, f_struct[0]])
folders = pd.concat([folders, f_struct[1]])
ym_cursor = ym_cursor + 1
files.reset_index(drop=True, inplace=True)
folders.reset_index(drop=True, inplace=True)
return files, folders
# f_str_p = get_myfiles_struct_period(tkn, 202203, 202204)
# f_str_p0 = f_str_p[0]
# Download files to dest_folder from from_ym to to_ym
# for vendor and data_abb.
# from_ym = 202305
# to_ym = 202305
# vendor = "ADVAN"
# data_abb = "WP"
def download_files(username, password, dest_folder,
from_ym, to_ym, vendor, data_abb, collapse=True, timeout=200):
token = get_access_token(username, password)
f_str_p = get_myfiles_struct_period(token, from_ym, to_ym)
f_str_p_files = f_str_p[0] # files
vendor_path = f"/{vendor}/{data_abb}"
f_str_p_files = f_str_p_files[f_str_p_files["parent"].str.endswith(vendor_path)]
f_str_p_files.reset_index(drop=True, inplace=True)
# parent_path = f_str_p_files.parent[0]
len_dewey_header = len(DEWEY_DATA_SUB_ROOT) + 1 # including last /
for i in range(0, f_str_p_files.shape[0]):
parent_path = f_str_p_files.parent[i]
parent_ym_vendor_path = parent_path[len_dewey_header:]
parent_ym_vendor_path = parent_ym_vendor_path.replace("/", "_")
src_url = f"{DEWEY_MP_ROOT}{f_str_p_files.url[i]}"
if (collapse == True):
dest_file = f"{dest_folder}/{parent_ym_vendor_path}_{f_str_p_files.name[i]}"
print(f"Downloading {dest_file}")
sys.stdout.flush()
# It seems token expires after some time.
# To download many files over a long period time, request tocken every time.
token = get_access_token(username, password)
download_file(token, src_url = src_url, dest_file=dest_file, timeout=300)
# Download files for 1 week to dest_folder
# mon_ymd = Monday year month date
# for vendoer and data_abb
# mon_ymd = 20200803
# vendor = "ADVAN"
# data_abb = "WP"
def download_weekly_files(username, password, dest_folder,
mon_ymd, vendor, data_abb, collapse=True, timeout=200):
token = get_access_token(username, password)
sub_path=f"/{mon_ymd//10000}/{(mon_ymd%10000)//100:02d}/{mon_ymd%100:02d}/{vendor}/{data_abb}"
response = requests.get(f"{DEWEY_DATA_ROOT}{sub_path}", headers={"Authorization": f"Bearer {token}"})
response_df = pd.DataFrame(response.json())
if response_df.shape[0] > 0:
files = response_df[response_df['directory']==False]
folders = response_df[response_df['directory']==True]
f_str_p_files = files
f_str_p_files.reset_index(drop=True, inplace=True)
# parent_path = f_str_p_files.parent[0]
len_dewey_header = len(DEWEY_DATA_SUB_ROOT) + 1 # including last /
for i in range(0, f_str_p_files.shape[0]):
parent_path = f_str_p_files.parent[i]
parent_ym_vendor_path = parent_path[len_dewey_header:]
parent_ym_vendor_path = parent_ym_vendor_path.replace("/", "_")
src_url = f"{DEWEY_MP_ROOT}{f_str_p_files.url[i]}"
if (collapse == True):
dest_file = f"{dest_folder}/{parent_ym_vendor_path}_{f_str_p_files.name[i]}"
print(f"Downloading {dest_file}")
sys.stdout.flush() # for R console.
# It seems token expires after some time.
# To download many files over a long period time, request tocken every time.
token = get_access_token(username, password)
download_file(token, src_url = src_url, dest_file=dest_file, timeout=300)
Below, the first function downloads all the files for a specific time period.
def download_files(username, password, dest_folder,
from_ym, to_ym, vendor, data_abb, collapse=True, timeout=200):
This function downloads files from Dewey using username and password to your local dest_folder for the period of from_ym to to_ym. You need to specify the data vendor and data_abb (data product). collapse does not do anything and just ignore it. timeout is session timeout.
Here is an example.
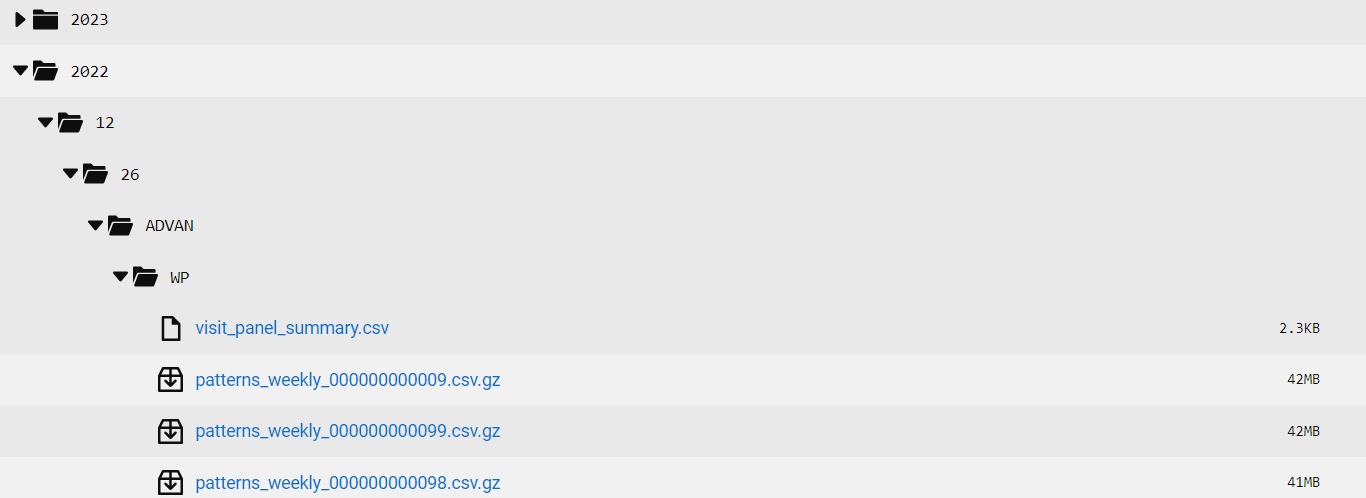
If you want to download ADVAN weekly patterns, you should have folders like the above. Then, to download from December 2022 to May 2023 to D:/temp folder use this:
download_files("user name", "password", "D:/temp", 202212, 202305, "ADVAN", "WP")
This will download all the files into one folder (D:/temp). Files will have headers like
2022_12_26_ADVAN_WP_xxxxxxx. ym format should be yyyymm in integer (e.g. 202103 for March 2021).
The last 26 is the Monday of the week, read from the Dewey folder because this is a weekly pattern.
Below, the second function downloads for one-week data.
def download_weekly_files(username, password, dest_folder,
mon_ymd, vendor, data_abb, collapse=True, timeout=200):
While using the download_files function overnight, I found sometimes some files had download errors. So, I downloaded that week’s data separately. For example, to download the week of December 26th, 2022, use
download_weekly_files("user name", "password", "D:/temp", 20221226, "ADVAN", "WP");
mon_ymd format should be yyyymmdd in integer (e.g. 20210308 for March 8th, 2021).
Thanks,
Donn