 This page is no longer being updated
This page is no longer being updated
For the latest updates and information, please refer to our new Dewey documentation page at docs.deweydata.io
The information for this page can be found on this page:
There was an upgrade in Dewey API to v3 from v2. This tutorial reflects the v3 API with additional convenience functionalities. I tried to maintain the tutorial as close to the v2 tutorial. Generic v3 API Python example code can be found here. R version tutorial is available here.
You can also find old version of this tutorial with the raw Python code here but there will be no more support on this legacy code (Bulk Data Downloading in Python (API v3)-depreciated - Help / Python - Dewey Community (deweydata.io)).
1. Create API Key
In the system, click Connections → Add Connection to create your API key.

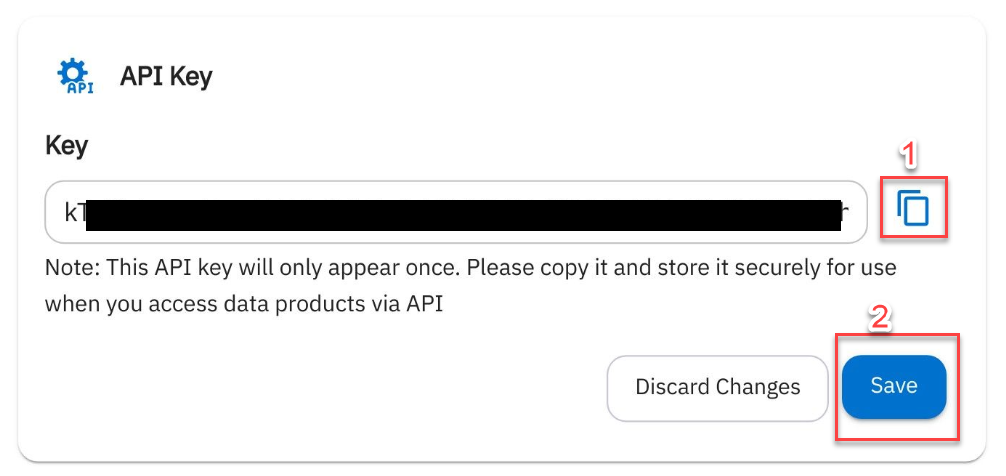
As the message says, please make a copy of your API key and store it somewhere. Also, please hit the Save button before use.
2. Get a product path
Choose your product and Get / Subscribe → Connect to API then you can get API endpoint (product path). Make a copy of it. You will notice that the path now includes “v3” instead of “v2”.

3. Python Code
Starting November 12, 2023, Dewey Data Inc. Python library (deweydatapy) is available on GitHub ( Dewey-Data/deweydatapy: Dewey Data Inc. Python API (github.com)). You can install the package by
pip install deweydatapy@git+https://github.com/Dewey-Data/deweydatapy
If you use PyCharm, [Python Packages] → [Add Package] → [From Version Control] → Select [Git] and input [https://github.com/Dewey-Data/deweydatapy].
Then, some example here (will not run)
# Using library
# Not run
import deweydatapy as ddp
apikey_ = "Your API key"
pp_ = "Your product path (API endpoint)"
files_df = ddp.get_file_list(apikey_, pp_)
ddp.download_files(files_df, "C:/Temp")
deweydatapy has the following functions:
get_file_list: gets the list of files in a DataFrameread_sample_data: read a sample of data for a file download URLread_sample_data0: read a sample of data for the first file with apikey and product pathread_local_data: read data from locally saved csv.gz filedownload_files: download files from the file list to a destination folderdownload_files0: download files with apikey and product path to a destination folderslice_files_df: slicefiles_df(retrieved byget_file_list) by date range
4. Examples
I am going to use Advan weekly pattern as an example.
# API Key
apikey_ = "Paste your API key from step 1 here."
# Advan product path
product_path_= "Paste product path from step 2 here."
You will only have one API Key while having different product paths for each product.
You can now see the list of files to download by
import deweydatapy as ddp
files_df = ddp.get_file_list(apikey_, product_path_, print_info = True);
files_df
print_info = True set to print the meta information of the files like below:
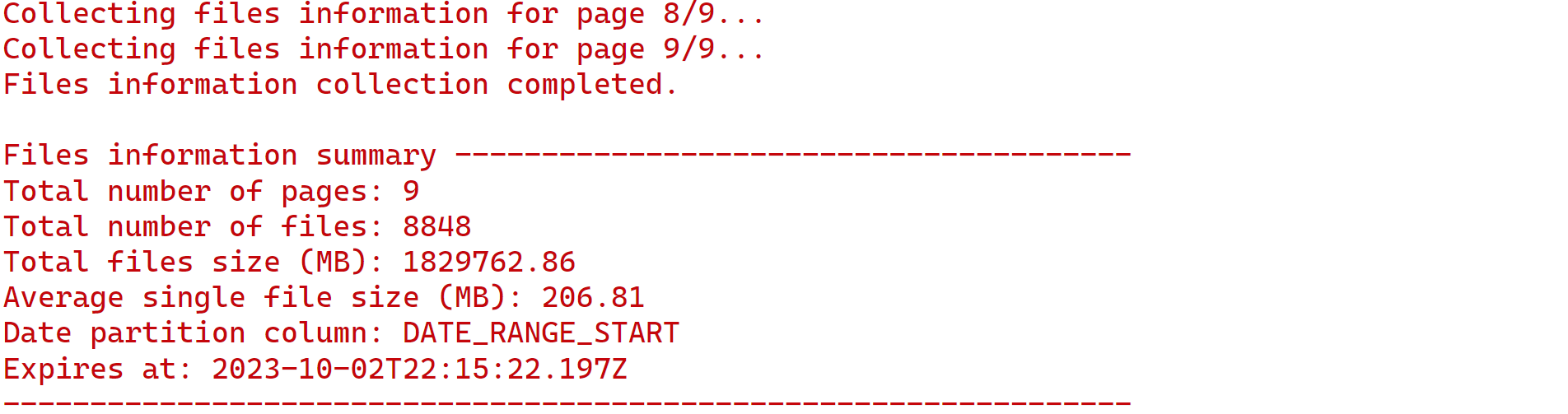
Advan weekly pattern data has a total of 8848 files over 9 pages, a total of 1.8TB, and 206.81MB average file sizes.
API v3 introduced the “page” concept that files are delivered on multiple pages. Each page includes about 1,000 files. So, if the data has 8848 files, then there will be 8 pages with 1,000 files each and the 9th page with 848 files. Thus, if you want to download files on pages 2 and 3, you can
files_df = ddp.get_file_list(apikey_, product_path_,
start_page = 2, end_page = 3, print_info = True);
Also, you can do this to download files from page 8 to all the rest
files_df = ddp.get_file_list(apikey_, product_path_,
start_page = 8, print_info = True);
files_df includes a file list (data.frame) like below:

The DataFrame has
indexfile index ranges from 0 to the number of files minus onepagepage of the filelinkfile download linkpartition_keyto subselect files based on datesfile_namefile_extensionfile_size_bytesmodified_atdownload_linkwhich is the same as thelink(download_linkis left there to be consistent with the v2 tutorial).
You can quickly load/see a sample data by
sample_data = ddp.read_sample_data(files_df['link'][0], nrows = 100)
This will load sample data for the first file in files_df (files_df['link'][0]) for the first 100 rows. You can see any files in the list.
If you want to see the first n rows of the first file skipping get_file_list, you can use
sample_data = ddp.read_sample_data0(apikey_, product_path_, nrows = 100);
This will load the first 100 rows for the first file of Advan data.
Now it’s time to download data to your local drive. First, you can download all the files by
ddp.download_files0(apikey_, product_path_, "E:/temp", "advan_wp_")
The third parameter is for your destination folder (“E:/temp”), and the last parameter (“advan_mp_”) is the filename prefix. So, all the files will be saved as “advan_wp_xxxxxxx.csv.gz”, etc. You can leave this empty or NULL not to have a prefix.
The second approach to download files is to pass files_df:
ddp.download_files(files_df, "E:/temp", "advan_wp_")
This will show the progress of your file download like below:
If some of the files are already downloaded and if you want to skip downloading them, set ddp.download_files(files_df, "E:/temp", "advan_wp_", skip_exists = True).
Sometimes, the download may stop/fail for any reason in the middle. If you want to resume from the last failure, then you can pass a slice of files_df. The progress shows file index = 2608 for example. If the process was failed on that file, you can resume from that file by
ddp.download_files(files_df[files_df['index']>=2608], "E:/temp", "advan_wp_")
Also, you may want to download incremental files, not all the files from the beginning. Then you can slice the data by date range. For example, to get the file list that falls between 2023-09-01 to 2023-09-10
sliced_files_df = ddp.slice_files_df(files_df, "2023-09-01", "2023-09-10")
and to get files from 2023-09-01 to all onward files
sliced_files_df = ddp.slice_files_df(files_df, "2023-09-01")
and then run
ddp.download_files(sliced_files_df, "E:/temp2")
You can quickly open a downloaded local file by
sample_local = ddp.read_local_data("E:/temp2/advan_wp_Weekly_Patterns_Foot_Traffic-0-DATE_RANGE_START-2019-01-07.csv.gz",
nrows = 100)
Thanks