Of course, you can read and take a look at Dewey datasets directly from a URL without downloading them to your hard drive. Sometimes, I want to see the data to get a quick idea about it. I will continue using the functions that I introduced in my previous post here.
I have weekly data sets looks like:
First, I want to look at one pattern file and here is how.
import gzip
from io import BytesIO
import traceback
# Directly read csv data from gz file
def read_data(token, file_url, timeout = 300):
# token = tkn
# file_url = "/api/data/v2/data/2022/12/26/ADVAN/WP/20221226-advan_wp_pat_part99_0"
# timeout = 300
src_url = DEWEY_MP_ROOT + file_url
response = requests.get(src_url, headers={"Authorization": "Bearer " + token}, timeout=timeout)
try:
csv_df = pd.read_csv(BytesIO(response.content), compression="gzip")
except gzip.BadGzipFile: # not gzip file. try normal csv
csv_df = pd.read_csv(BytesIO(response.content))
except:
print("Could not read the data. Can only open gzip csv file or csv file.")
return csv_df
This function works for either gz or csv files (you don’t need to specify file types). If you click “!” mark from your data folder, you can see the File Information below and can copy the file URL (file_url) to your clipboard by clicking the button.
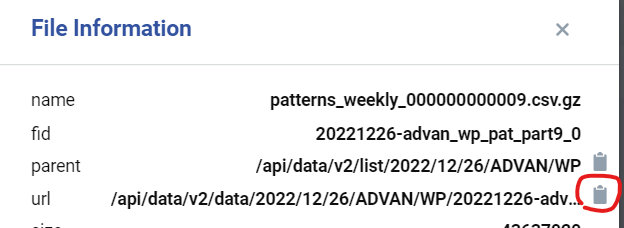
Once have your URL in the clipboard, you are ready to go.
tkn = get_access_token(user_name, pass_word)
tkn
# *.gz file
pattern_df = read_data(tkn, "/api/data/v2/data/2022/12/26/ADVAN/WP/20221226-advan_wp_pat_part99_0")
# *.csv file
panel_summary_df = read_data(tkn, "/api/data/v2/data/2022/12/19/ADVAN/WP/20221219-advan_wp_visit_panel_0")
The file_url of “/api/data/v2/data/2022/12/26/ADVAN/WP/20221226-advan_wp_pat_part99_0” is from your clipboard Ctrl + V.
Actually, a weekly pattern is broken into multiple files (~170 in my case), and if you only look at one file, you may lose the big picture. I wanted to check the POI coverage of the dataset. So, I looked at the Target stores in Los Angeles, CA, USA, for one week, the week of 12/26/2022.
# 1 week data ----------------------
file_paths = get_file_paths(tkn, "/2022/12/26/ADVAN/WP")
# only files end with .gz
pattern_paths = file_paths[file_paths['name'].str.endswith('.gz')]
# reset data frame index
pattern_paths.reset_index(drop=True, inplace=True)
n_files = pattern_paths.shape[0]
# print a sample url
pattern_paths.loc[0, "url"];
# buffer to save data
buff_df = None
for i in range(0, n_files):
print("processing " + str(i) + "/" + str(n_files-1))
# read one file from url
pattern_df = read_data(tkn, pattern_paths.loc[i, "url"])
# city field is not na
pattern_sub_df = pattern_df[~pattern_df["city"].isna()]
# CA, Los Angeles, Target
pattern_sub_df = pattern_sub_df[(pattern_sub_df["region"] == "CA") &
(pattern_sub_df["city"] == "Los Angeles") &
(pattern_sub_df["brands"] == "Target")]
# keep binding newly found patterns.
if(pattern_sub_df.shape[0]>0):
print("found " + str(pattern_sub_df.shape[0]))
buff_df = pd.concat([buff_df, pattern_sub_df], axis= 0)
# buff_df has all the patterns for Targets in Los Angeles, CA
# print unique store ids
pd.unique(buff_df["store_id"])
Now, the buff_df has all the patterns for the Target stores in Los Angeles, CA. It turned out Advan data covers 17 stores. One website says there are 19 Target stores in Los Angeles. So, I guess I am good to move forward.
Thanks,
Donn