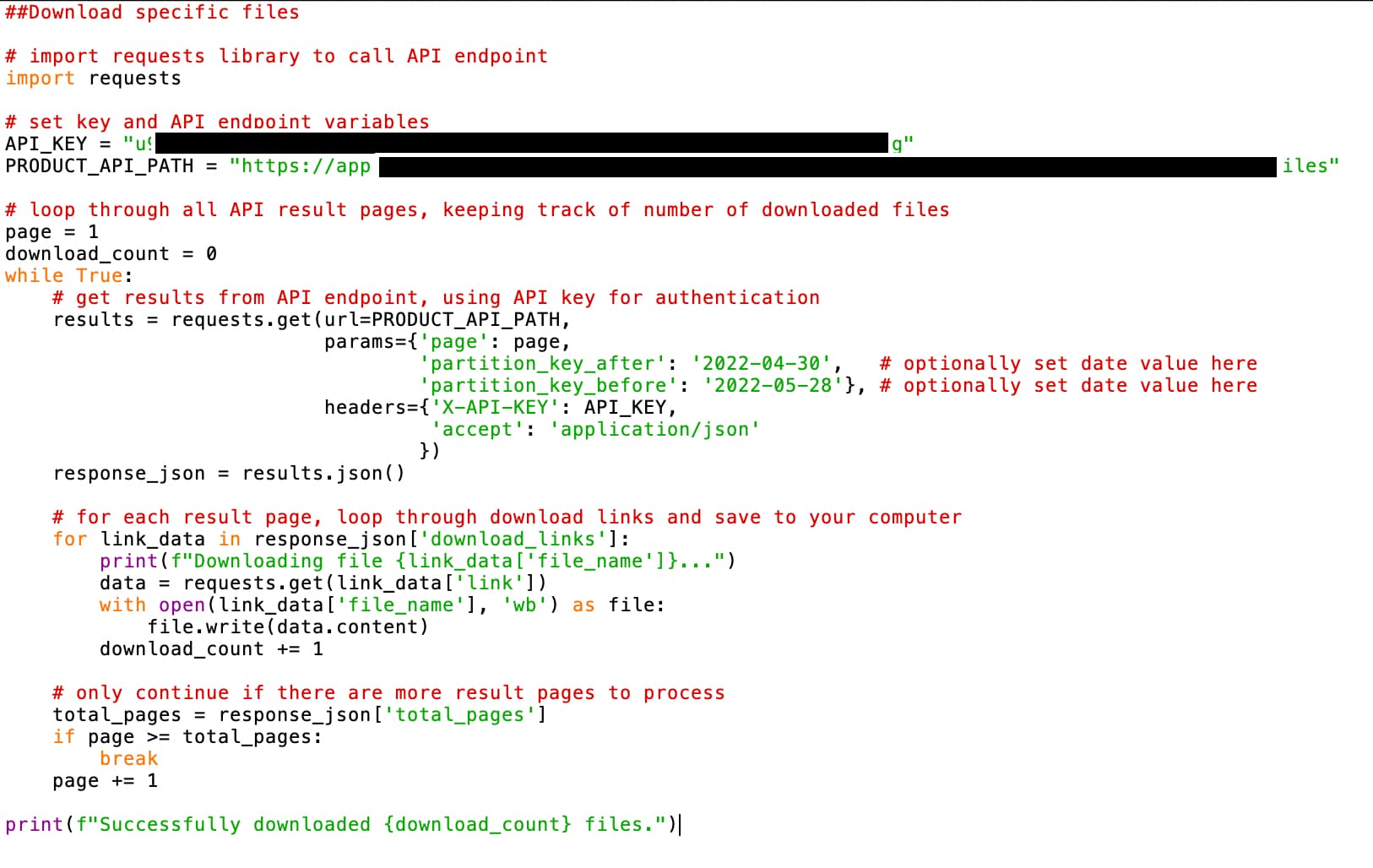
This code below seems to work in terms of downloading data. I specified the date range needed in order to speed up the process. However, how do I specify the location (state, city, etc.) and places I want to look at as well, i.e. grocery stores?
Also, how do I open the downloaded files (I’m using a Mac)? I compressed the .gz file, then I doubled clicked the zip file and it showed as a .csv 2 file. When I clicked that, it opened into a text file but I was hoping it opened in excel or google sheets. I want to read that file into Stata, but I’m having some trouble.
I was able to figure out how to open the file. However I am still in need of help with specifying the location of places that I want to look at/download.
Currently, we’re unable to support location-based partitioning using the API for some of the larger products. The only way to filter them down via the API is by date. Any additional filtering will need to happen after the data has been downloaded.
It depends on which product you are looking at, but the API response contains an avg_file_size_for_page field you can use to see the size of individual files.
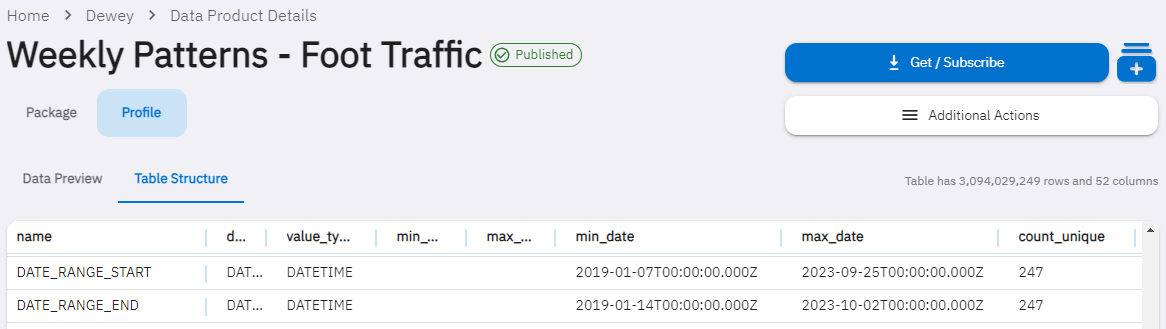
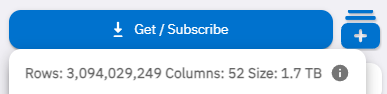
You can also see the date range on the Table Structure page, and the total size in the Get/Subscribe modal:
I am looking at the weekly patterns data. I see that the entire dataset is 1.7 TB but I was wondering how big the file is to download a weeks worth of data i.e. 5/6/23 - 5/13/23. Ideally I want to download a couple of weeks but I need to know the size first to make sure I will have enough space.
The API response has the total_size as an output - see documentation here.
For the weekly patterns dataset for 5/8/23-5/14/23, looks like there are 36 zipped files, each with a size around 207MB, leading to a total size of ~7.5GB for the week. Note that since these are compressed, the uncompressed size can be 5-10x that.